AWS Big Data Blog
Introducing Cold Storage for Amazon OpenSearch Service

Log analytics is the most popular use case for Amazon OpenSearch Service, and with the modern-day advent of the architectural tenet to log everything all the time, it can be a challenge to store and analyze this exponential data growth effectively with a minimal price-to-performance tag. With a proliferating number of applications, log volume to be analyzed is exploding. The value of log data can transition from high for most recent data to historical in a matter of weeks or days. This rapid transition presents a significant cost challenge for historical data, be it for compliance or ad hoc analysis, to justify the storage cost to derive potential business insights from this data.
In May 2020, we announced the general availability of UltraWarm for Amazon OpenSearch Service, which enabled a cost-efficient and performant solution for older data. UltraWarm scaled the benefits of a hot domain configuration for Amazon OpenSearch Service by using a combination of Amazon Simple Storage Service (Amazon S3) and optimized compute nodes to provide a hot-like experience using stack-wide granular caching, adaptive prefetching, and query optimizations.
Today, we introduce cold storage for Amazon OpenSearch Service – a fully managed, low cost storage tier that makes it easy to durably store historical data and analyze on-demand, at a lower cost than other storage tiers. Cold storage is a great fit for scenarios in which a low ROI necessitates an archive or delete action on historical data, or if you need to conduct research or perform forensic analysis on older data with Amazon OpenSearch Service. The following diagram illustrates Amazon OpenSearch Service domain architecture that includes hot storage, UltraWarm and cold storage.

Cold storage builds on UltraWarm to further provide a hot-warm-cold domain configuration by decoupling compute from storage. It also significantly reduces your per GB storage costs to near Amazon S3 prices. You can selectively attach the cold data to your existing UltraWarm nodes in seconds and gain valuable insights. Additionally, cold storage offers an alternative to other high operational overhead methods to store and query historical data, with fully integrated and readily accessible data as part of your existing Amazon OpenSearch Service domain.
Amazon OpenSearch Service customers who tried the beta version of this feature, shared the following observations.
“During beta testing, our users were able to migrate non-production logs from cold to warm within seconds, directly from the Kibana interface,” said Seth Carroll, Principal DevOps Engineer at Capital One. “The index state management policies made it really easy to automatically transition data between hot, warm, and cold. Cold storage will simplify the process of performing ad hoc analysis on historical log data.”
“Amazon OpenSearch Service cold storage helps us to increase our log retention timeframe at a much lower cost. Kibana integration is simple and seamless to use, has no additional operational overhead, and helps our team self-serve their requests without compromising query performance,” said Raghu Chandran, Sr. Systems Engineer at Verizon Communications. “Enabling cold storage on our existing cluster was quick and simple,” said Vijaya Lakshmi Durga Tokala, Systems Engineering Consultant at Verizon Communications.
Cold storage feature highlights
In addition to offering the lowest storage cost per GB than other storage tiers on Amazon OpenSearch Service, cold storage also includes a powerful set of features that helps you expand the data you can analyze, using the familiar capabilities provided by Amazon OpenSearch Service.
- The cold storage tier is built for scale allowing you to store any amount of data.
- Decoupling compute helps you save by paying near Amazon S3 prices for data storage.
- Within seconds, you can move historical and infrequently accessed data from warm to cold while keeping the data readily available to discover and search.
- You can perform on-demand analysis by attaching cold data to your existing UltraWarm nodes in seconds.
- You can use the Kibana interface, Index State Management (ISM) policies, and cold storage APIs to manage the lifecycle of your cold data.
- You can apply existing security and fine-grained access control policies for queries after the cold data is moved to warm.
- Experience identical performance as your warm data (when attached to the UltraWarm data nodes).
Kibana for cold storage
Cold storage seamlessly integrates with the existing Kibana interface in Amazon OpenSearch Service. The Index Management view in Kibana has been redesigned to list indices by the storage tier they belong to, which simplifies data discovery and actions for the corresponding storage tier. For example, the Warm Indices page lists existing warm indices on your cluster.
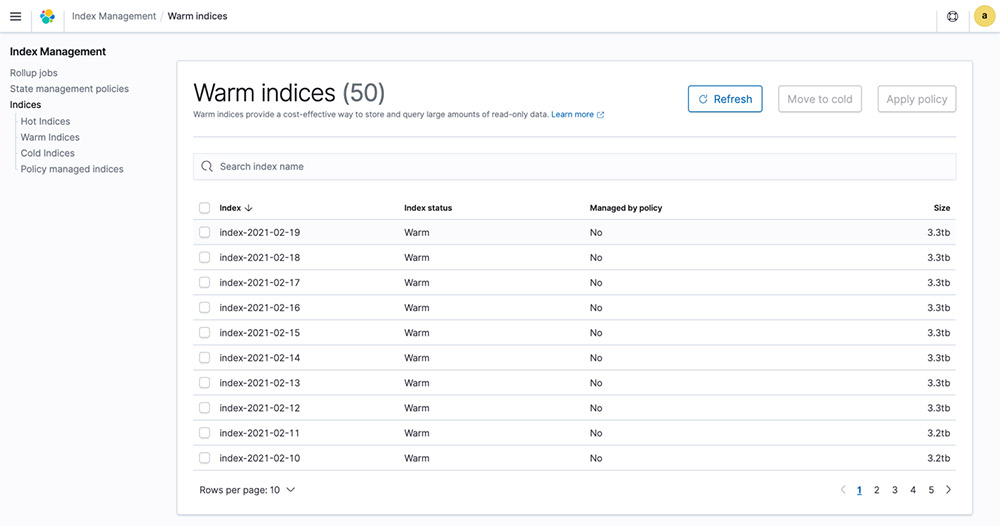
Moving an index from warm to cold
You can manually select an index and move it from warm to cold by choosing Move to cold.
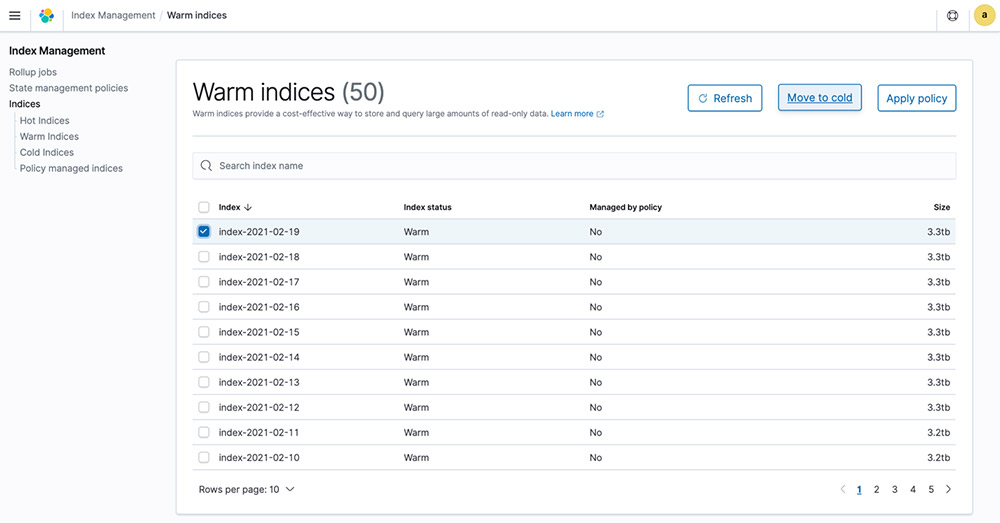
To simplify discovery, you’re prompted to provide a time range for the data in this index. You can select a timestamp field from an auto-populated list based on the data in your index, manually provide the start and end timestamp for the data in the index, or simply choose to not specify one.
After you choose Move index, within seconds, your index moves from warm to cold.

Discover and move indices from cold to warm
When you need to query your cold data, you can selectively attach it to your UltraWarm nodes. You can discover and filter through the list of cold indices in your cluster on the Cold Indices page. Provide a filter criteria such as an index pattern as well as a start and end timestamp for the index data.
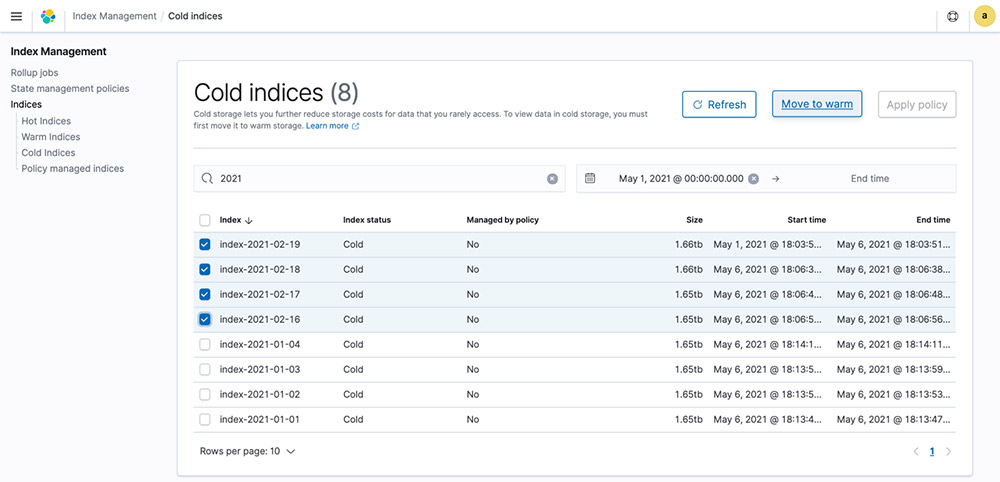
After you select the indices you need, choose Move to warm. A pop-up appears that shows the number of indices being moved and the required storage space that the selected indices will use once moved to warm. After you proceed, your indices are moved to warm within seconds, where you can interactively analyze this data. For most cold to warm move requests, the performance impact on your cluster is negligible, as the move is powered by the UltraWarm nodes that use an optimized algorithm to fetch minimal metadata for initialization, allowing you to query your data right away.
When you try to move large amounts of cold data into warm, you may need to add additional UltraWarm data nodes to accommodate the storage requirement of your request. You can do so from the AWS Management console, AWS SDK, or AWS CLI. After you add the UltraWarm nodes, you can retry any failed requests.
Programmatic access using APIs
Cold storage adds support for new APIs to support migration of data between warm and cold tiers, discover cold data using index patterns and timestamps, check migration status, and delete indices or update metadata. For more information on API support, see Cold storage for Amazon OpenSearch Service .
Integration with Index State Management policies
Along with the existing Open Distro for Elasticsearch support actions and the warm_migration action available with ISM in Amazon OpenSearch Service, we’re introducing new actions to support the migration of indices between warm and cold. For more information on ISM policies, see Index State Management in Amazon OpenSearch Service.
Availability
Cold storage is available for all Amazon OpenSearch Service domains version 7.9 or higher, across all commercial AWS Regions. For a complete list of supported AWS Regions, see the What’s New post.
Conclusion
Cold storage for Amazon OpenSearch Service is a fully managed storage tier that makes it easy to durably store historical data and analyze on demand, at a lower cost than other Amazon OpenSearch Service storage tiers. To start using cold storage, sign in to the AWS Management console, use the AWS SDK, or AWS CLI, and enable cold storage.
About the Authors

Imtiaz (Taz) Sayed is the WW Analytics Tech Leader at AWS. He enjoys engaging with the wider data and analytics community, and architecting solutions for his customers to help maximize the value of their data.
 Jimish Shah is a Senior Product Manager-Technical at AWS with over a decade of diverse experience bringing products to market in log analytics, cybersecurity, and IP video streaming domains.
Jimish Shah is a Senior Product Manager-Technical at AWS with over a decade of diverse experience bringing products to market in log analytics, cybersecurity, and IP video streaming domains.